Computational Statistics
Daily
Syllabus
Class Notes
Project
Project Assignment
Group Roles
Rubric
Data Sources
Clicker Q
GitHub
Computational Statistics
01. Start with R + Git
The importance of reproducibility. Ideas of computational statistics, data science, and machine learning. Some resources for starting with R + RStudio + Git + GitHub.
Aug 25, 2025
Jo Hardin
02. Data Viz
Examples, good and bad. Theory underlying what makes a viz good and bad. Tools to implement viz tasks.
Aug 27, 2025
Jo Hardin
03. Wrangling
Data wrangling skills are among the most important to hone.
Sep 3, 2025
Jo Hardin
04. Simulating
Simulating scenarios, simulating datasets, simulating random variables.
Sep 8, 2025
Johanna Hardin
05. Permutation Tests
Simulating scenarios, simulating datasets, simulating random variables.
Sep 22, 2025
Johanna Hardin
06. Bootstrapping
The sample as a proxy for the unknown population. Sample from said proxy population (i.e., the sample) to generate a sampling distribution. Bootstrap.
Oct 1, 2025
Johanna Hardin
07. Recipes + k-NN
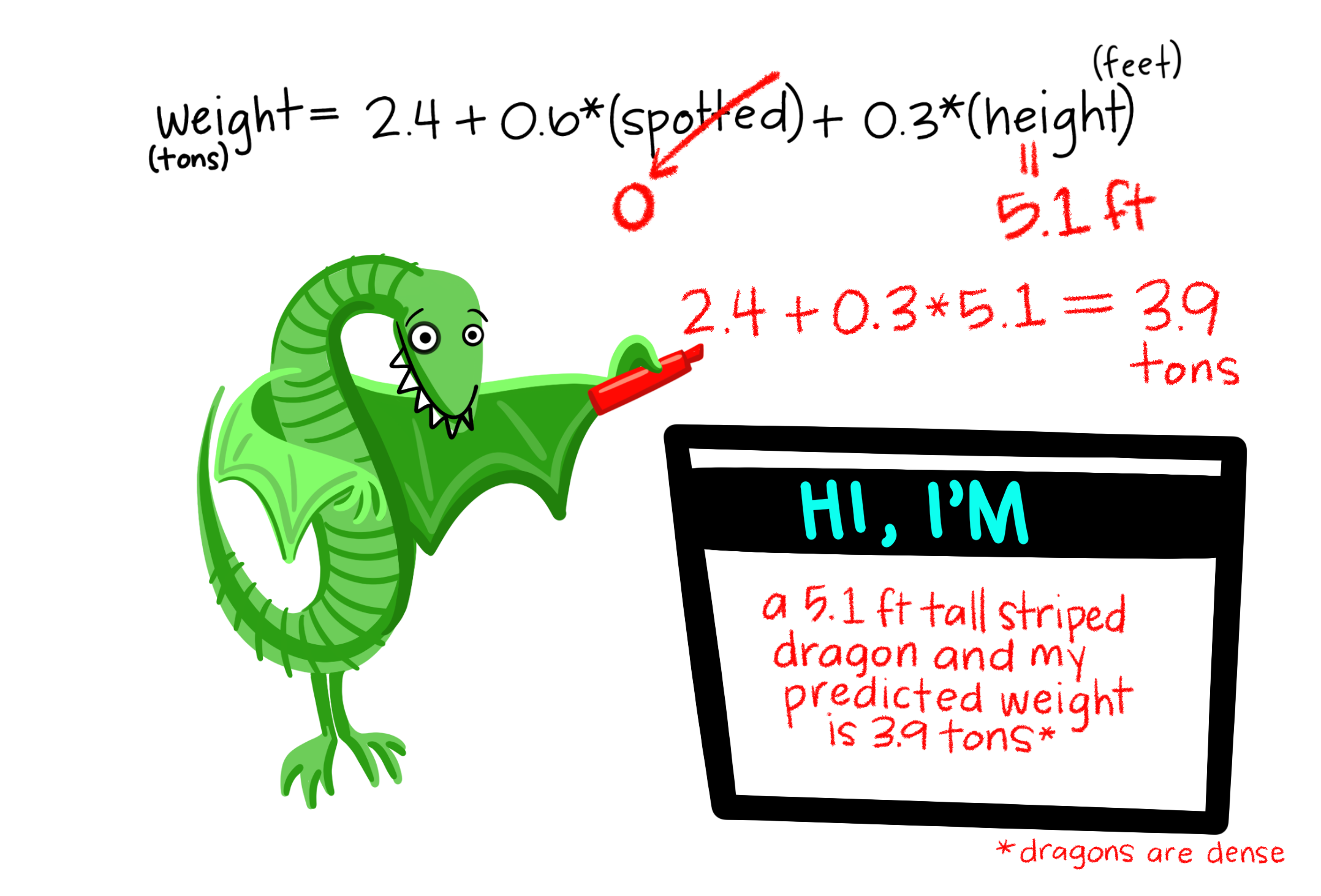
And old adage says: garbage in, garbage out. Here we avoid garbage in. k-Nearest Neighbors is a classification algorithm based on the premise that points which are close to one another (in some predictor space) are likely to be similar with respect to the outcome variable.
Oct 20, 2025
Johanna Hardin
08. Trees
Trees represent a set of methods where prediction is given by majority vote or average outcome based on a partition of the predictor space.
Oct 27, 2025
Johanna Hardin
09. Random Forests
Many trees make a forest. Bagging gives FREE independent model assessment or parameter tuning. Random Forests have a fantastic variance - bias trade-off.
Nov 3, 2025
Johanna Hardin
10. Support Vector Machines
Here, support vector machines will be used only to classify objects which can be categorized into one of exactly two classes. As with other classification and regression methods, support vector machines as a method can be used more generally. However, we will work to understand the mathematical derivation of the binary-classification SVM.
Nov 10, 2025
Johanna Hardin
11. Unsupervised Learning
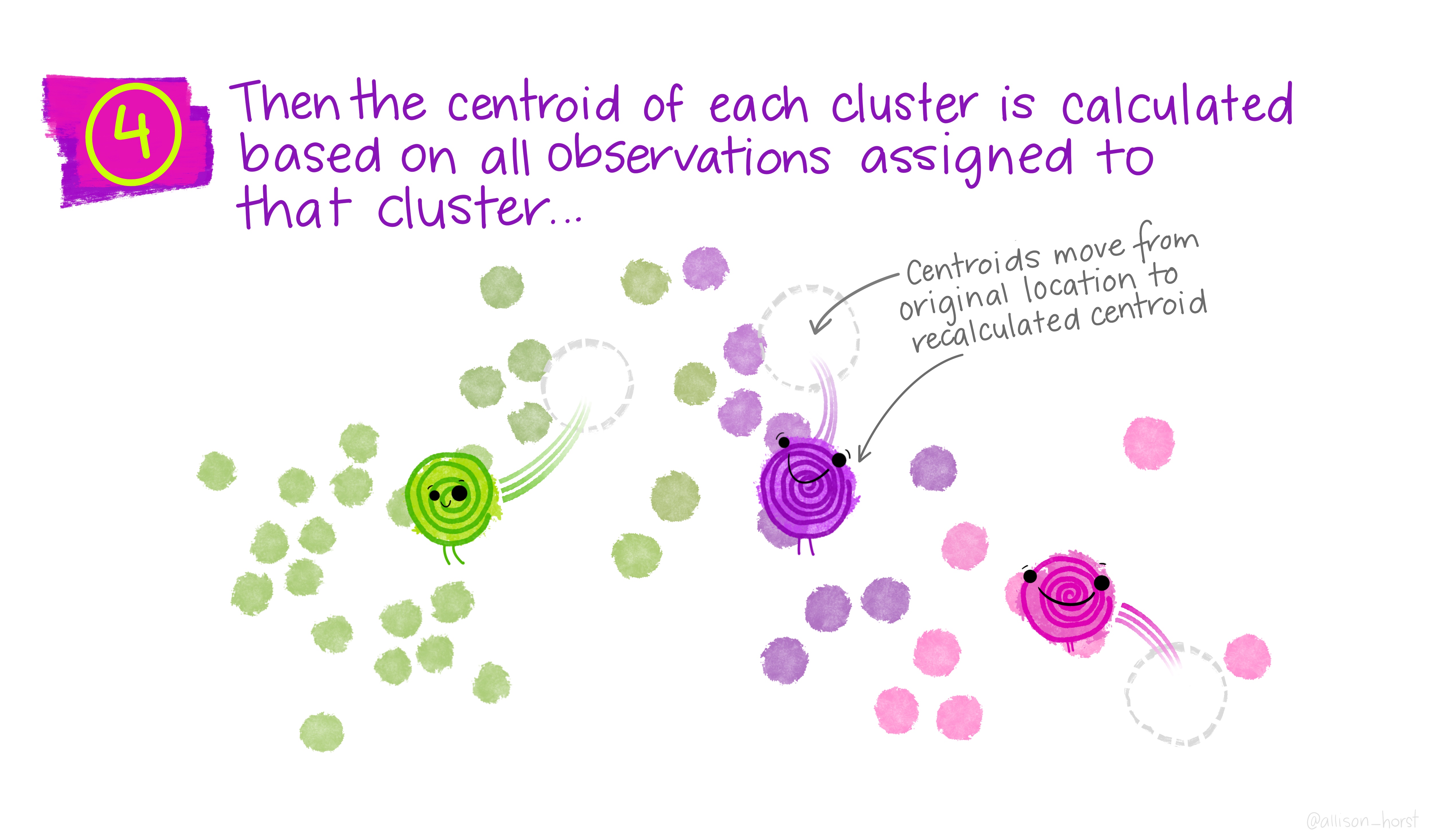
A quick dive into unsupervised methods. We cover two clutering methods: hierarchical and partitioning (k-means and k-medoids). Additionally, we discuss latent Dirichlet allocation (LDA).
Nov 19, 2025
Johanna Hardin
No matching items
Reuse
CC BY 4.0