Figure 1: Artwork by @allison_horst.
Agenda
November 16, 2021
- unsupervised methods
November 18, 2021
- k-means clustering
- k-medoid clustering
November 23, 2021
- hierarchical clustering
Readings
Class notes: Unsupervised Learning
Gareth, Witten, Hastie, and Tibshirani (2021), Unsupervised Learning (Chapter 12) Introduction to Statistical Learning.
Reflection questions
Why does the plot of within-cluster sum of squares vs. \(k\) make an elbow-shape (hint: think about \(k\) as it ranges from 1 to \(n)?\)
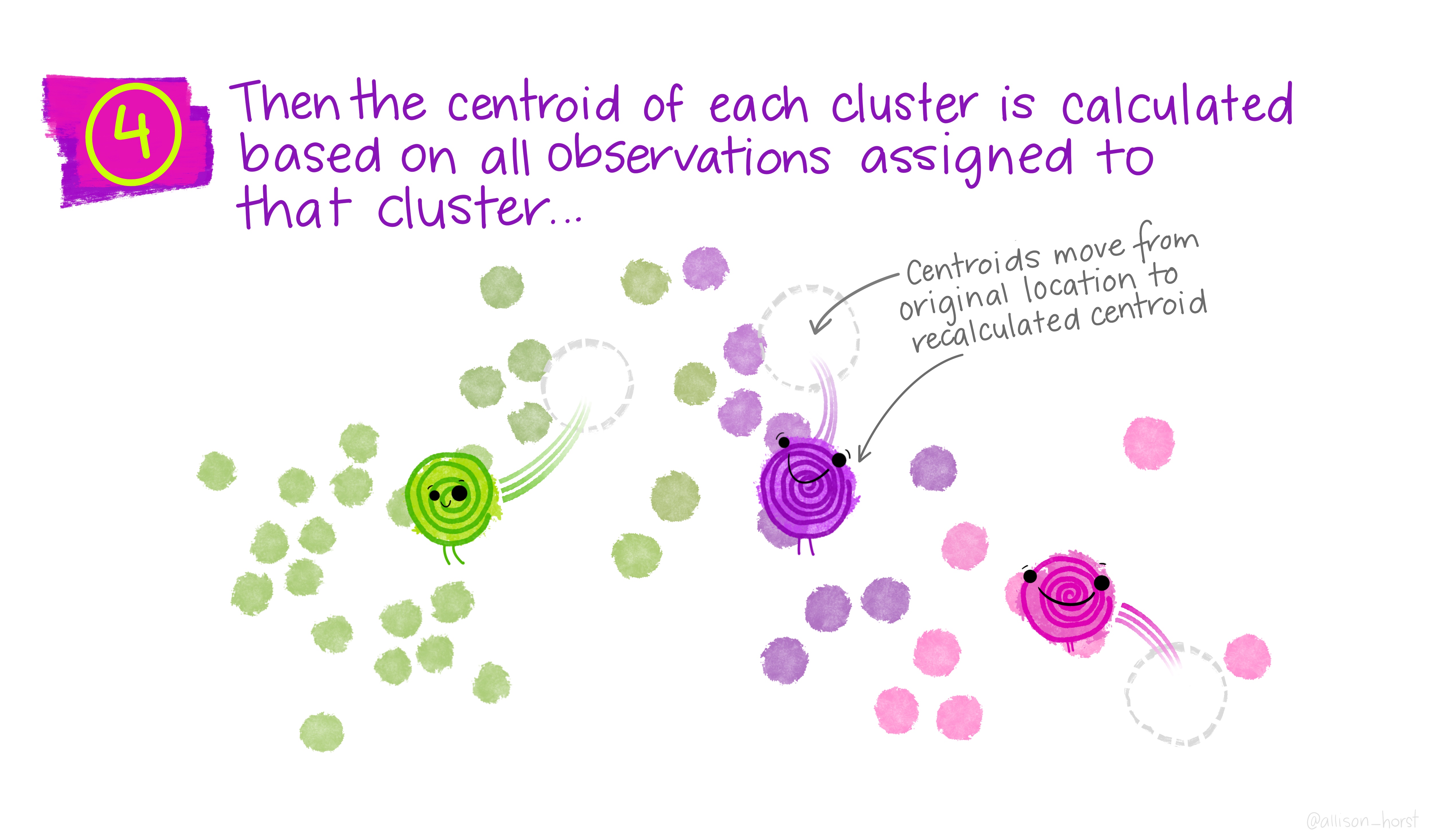
How are the centers of the clusters in \(k\)-means calculated? What about in \(k\)-medoids?
Will a different initialization of the cluster centers always produce the same cluster output?
How do distance metrics change a hierarchical clustering?
How can you choose \(k\) with hierarchical clustering?
What is the difference between single, average, and complete linkage in hierarchical clustering?
What is the difference between agglomerative and divisive hierarchical clustering?
Ethics considerations
What type of feature engineering is required for \(k\)-means / hierarchical clustering?
How do you (can you?) know if your clustering has uncovered any real patterns in the data?
Slides
In class slides - clustering for 11/18/21 and 11/23/21.
Additional Resources
Fantastic k-means applet by Naftali Harris.
Network Analysis of political books – Bridging the divide: political books